机器人声学降噪的能力和原理
音频处理的能力和原理
当用户对机器说“我想听陈粒的歌”时,机器首先要通过“耳朵”来听用户说了什么。
麦克风阵列在其中就充当了“耳朵”的角色。麦克风,就是我们常见的话筒,麦克风阵列本质上和话筒没有区别,只是收音的单元比较多而已,基本上超过两个收音孔就可以说是麦克风阵列了。简单理解为一个麦克风就是麦克风,多个麦克风就是麦克风阵列。
机器听到的声音总是噪声和信号夹杂在一起,就需要对音频本身进行处理。
也就是说,麦克风阵列除了看到的麦克风数量以外,还有一系列的前端算法,两者结合的系统才是完整的麦克风阵列。
而麦克风阵列也只是完成了物理世界的音频信号处理,想要完成语音识别,还是需要云端的ASR模型,两个系统配合在一起才能得到最好的识别效果。
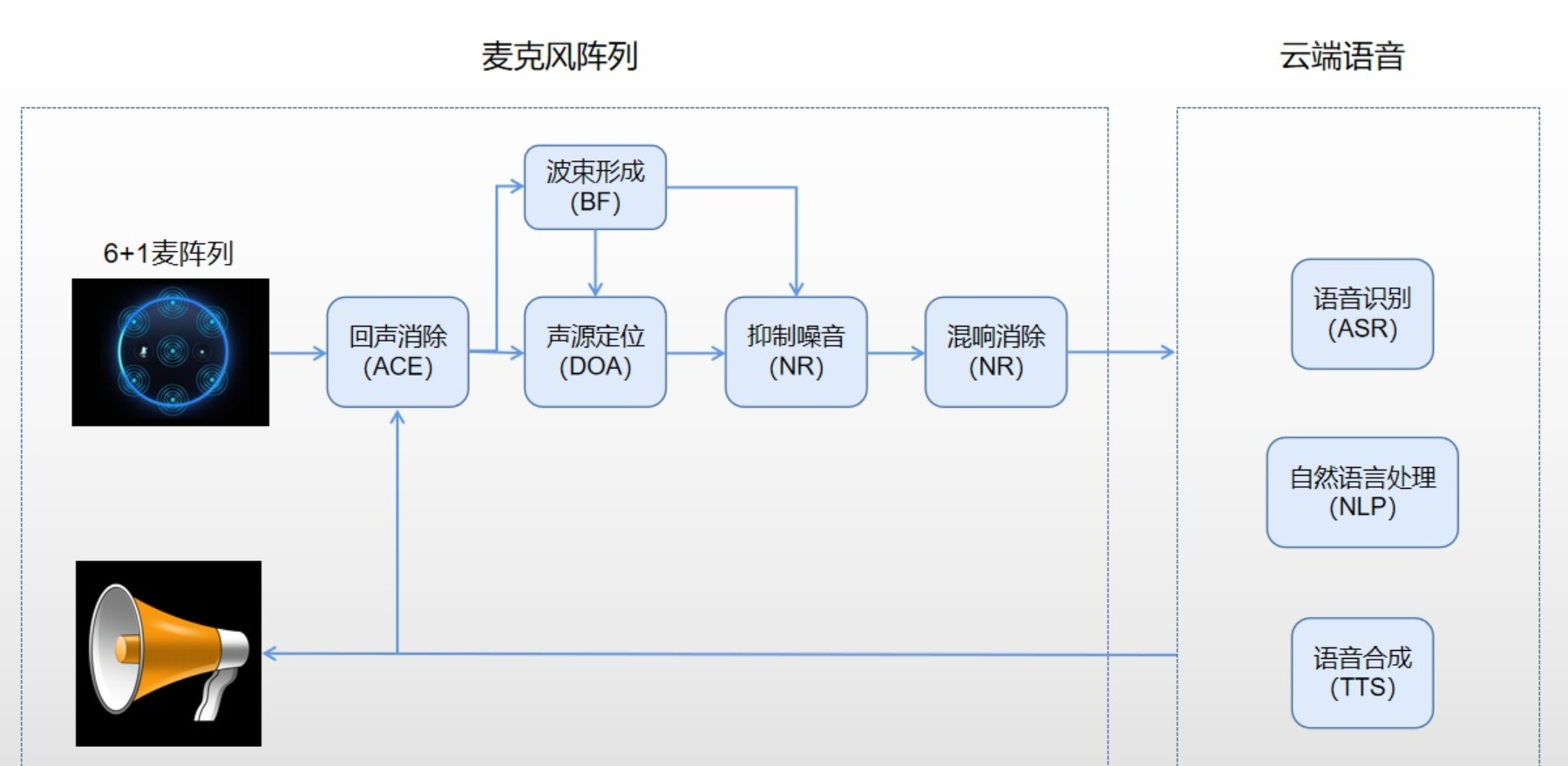
1. 音频处理前端功能概述
降噪
降噪也就是抑制噪声,分为被动降噪和主动降噪。
被动降噪,指的是采用一些外部手段来抑制噪声,如捂住耳朵、使用厚耳罩等,都属于使用被动降噪。
主动降噪active noise control(ANC),也叫主动减噪(active noise reduction)或消噪(noise cancellation)。主动降噪是利用声波干涉的原理,通过加入一段反噪声的信号到噪声信号中,达到降低噪音信号的目的。

也就是说,原有的噪声和加入的声波处处相反,彼此抵消,噪声就被消除或降低了。
声源定位
人有两个耳朵,可以通过声音判断发声的方向,机器人也同样可以做到。这个功能就是声源定位,通过声音感知人所在的方向,从而实现对目标声源方向的跟踪。这也为后续的波束形成做技术铺垫。
比如,我们在机器人左边叫它,机器人听到声音后就会把头转向左边,我们在机器人背后叫它,机器人听到声音后就会转过去,这就是声源定位最典型的应用。通常声源定位会应用在语音唤醒阶段,能够检测一个大致的方向。
常用到的技术是TDOA(Time Difference Of Arrival,到达时间差),简单理解就是通过计算信号到达麦克风之间的时间差,从而计算出声源的位置坐标,需要毫秒级的响应和计算。

语音增强
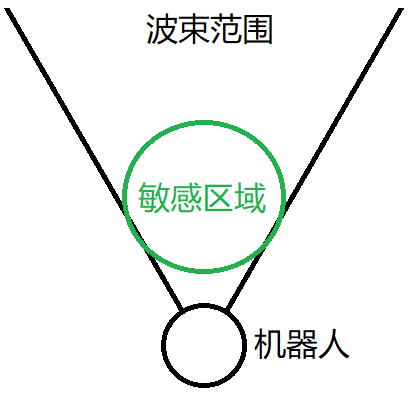
当机器被唤醒后,前端算法使用波束成形的方法,向指定方向构造一个大约60度的扇形波束,对这个范围内的语音信号敏感,抑制来自波束外的所有声音。
这是由于,在语音识别中,语音信息中往往夹杂着噪音,常见的有环境噪音和人声干扰,通常不会掩盖正常的语音,只是影响声音的清晰度。麦克风阵列主要通过波束形成技术,来抑制噪音,增强人声。可以理解为只识别大约60度范围内的声音(一般角度可以进行调节),其他角度的声音都会受到抑制,从而实现抑制噪音的目的。反过来增强角度内的人声,也就是增强人声。

波束成形(beamforming),又叫波束赋形、空域滤波。它的原理是,通过对多路麦克风信号加权求和、滤波等处理,抑制非目标方向的干扰,增强目标方向的声音,最终输出期望方向的语音,相当于形成一个“波束”。
通过这样的方式,可以很大程度上抑制噪声和其他语音对机器听觉产生的干扰。
回声消除/自识别
如果不做特殊处理的话,机器人会识别自己发出来的声音,很有可能就会变成无休止的自问自答,或者拾音错误。回声消除就是为了解决这个问题,消除掉机器自己发出的声音。
比如机器人正在放音乐周杰伦的新歌,但是用户想要查一下天气,这个时候你就会说“小X小X,今天天气”。回声消除的目的就是要去掉其中音乐信息而保留用户的声音。
回声消除,有时也被称作为“自识别”,即机器识别自己发出的声音。
混响消除
在某些场景,发音会有回音,人能听到的是17米左右距离返回的回音。但是机器的感知要比人敏感的的多,如果不做处理,就会出现一句话叠加识别的情况。混响常指声波在室内传播时,被墙壁、天花板、地板等障碍物形成反射声,并和直达声形成叠加的现象。
比如在演播厅,我们能够感受到较为明显的回音,机器同样能够识别到这些回音。混响消除就是消除之后带来的回音,只识别第一遍的内容。
解决了这些问题,基本上就可以在日常环境下进行一个正常拾音,从而保证整个语音识别的正常。
猎户星空已经发展了两代音频处理前端算法,正在开发第三代算法。
2. 猎户星空音频前端算法发展路径
第一代音频前端算法
用于豹小秘1.0。
实现的效果是,在语音信号和噪音的平均强度一样(信噪比0bd)时,语音识别准确率仍然可以达到90%。
与竞品相比,优于科大讯飞、微纳感知和声智的算法,与大象声科算法接近(略弱)。
第二代音频前端算法
用于豹小秘mini、豹小秘1.5、招财豹机器人。
第二代音频前端算法的功能与第一代算法基本相同,主要是增强了基于波束成形的语音增强信号输出。
实现的效果是,在噪音的平均强度是语音信号的约3.2倍(信噪比-5bd)时,语音识别准确率仍然可以达到90%。
与竞品相比,在有噪声的环境对比中,语音识别准确率优于豹小秘1.0、克鲁泽、云帆、优友和temi等所有一流竞品。
第三代音频前端算法
新一代算法正在研发阶段,将继续提升低信噪比环境下的语音质量,使机器人听觉的抗噪声能力接近人类,能工作在更嘈杂的环境下。
算法还将提供设置敏感区域,即,进一步精确声音来源的范围,而不仅仅是波束的能力,只拾取指定的敏感区域内的语音信号,从而进一步消除波束范围内其他声音对语音识别的干扰。